On the Stability of Open-Set Recognition via Target-Dampened Knowledge Distillation in Single-Channel Vision Models
Abstract
This phase introduces a highly compressed MobileNetV3 architecture trained to classify 1,025 fine-grained species from binary silhouettes while concurrently rejecting open-set topological noise. Because binary silhouettes lack color and internal texture, conventional convolutional heuristics fail, forcing the network to rely strictly on shape geometry. To achieve production-grade latency without sacrificing the representational capacity of deeper networks, a Knowledge Distillation framework is employed, compressing a 230 MB ensemble of five ResNet-18 models into a 66.6 MB MobileNetV3 student. The training corpus comprises over 55,000 heterogeneous samples. To enforce robust open-set recognition, a heavily penalized out-of-distribution class populated with abstract COCO geometries was integrated into the loss function with an aggressive dampening weight (γ = 7.8).
Evaluated on a strict holdout test set across three independent random seeds, the distilled student achieved a mean Top-1 accuracy of 90.24% (±0.10%), a Top-5 accuracy of 91.54% (±0.01%), and a Macro F1-Score of 0.9569 (±0.0014). The OOD boundary achieved an AUROC of 0.9998. Component analyses targeting the distillation coefficient (α) and the OOD penalty (γ) isolate the architectural contributions. Post-training confusion analysis reveals that geometric errors are not stochastic but morphologically deterministic, converging heavily on specific highly occluded topologies. These results demonstrate that target-dampened distillation on single-channel data yields deterministic, highly calibrated decision boundaries suitable for edge-deployed computer vision.
1. Introduction
Phase I demonstrated that an ensemble of five ResNet-18 models achieves 80.87% Top-1 accuracy on 1,025-class silhouette classification. However, deploying 230 MB of parameters in a CPU-only production environment (HuggingFace Spaces Free Tier) introduces prohibitive latency costs. The objective of Phase II is to compress the ensemble's geometric knowledge into a single lightweight model while simultaneously engineering a robust open-set decision boundary.
While deep CNNs excel at this task, deploying heavily parameterized models in production environments introduces prohibitive latency and memory costs. Transitioning to lightweight edge architectures, such as MobileNetV3, typically incurs a severe accuracy penalty on tasks requiring fine-grained topological discernment. Furthermore, lightweight models suffer from acute softmax overconfidence when confronted with Out-of-Distribution data, classifying random abstract shapes as known categories with artificial certainty.
To bridge this gap, a target-dampened Knowledge Distillation approach is proposed. By aligning the student network's gradients with the soft labels of a robust ResNet-18 ensemble and explicitly forcing the topological separation of abstract noise via an aggressively weighted Open-Set penalty, state-of-the-art stability and compression are achieved.
2. Methodology
2.1. Deterministic Preprocessing Pipeline
Each sample passes through a fixed transformation pipeline designed to eliminate spatial variance and reduce the input to pure topological information. Source images in RGBA format are segmented via the alpha channel — pixels with opacity above 50% are mapped to black (0), all others to white (255) — producing a clean binary mask. The bounding box of the active pixels is computed dynamically and the image is tightly cropped, removing irrelevant empty margins. To avoid distorting body proportions, the cropped mask is centered on a square canvas with 20% padding on all sides, ensuring that extremities — wings, tails, antennae — remain clear of the tensor boundary.
Finally, the result is converted to a single-channel grayscale tensor at 128×128 pixels and normalized to support gradient convergence during backpropagation. This pipeline is applied identically to both the 1,025 target species and the 1,957 COCO OOD masks, ensuring parity that prevents the network from exploiting low-level artifacts.

2.2. Stochastic Data Augmentation and Invariant Alignment
To prevent spatial memorization and push the model toward learning underlying geometric features rather than specific pixel distributions, a rigorous stochastic augmentation pipeline was applied during training. Three operations were structured to enforce invariance to pose, orientation, and occlusion.
Random Rotation and Spatial Translation subtly shifts the silhouette orientation (maximum 10 degrees) while filling exposed canvas bounds with pure white (255). Random Horizontal Flipis applied with p = 0.5: because the teacher ensemble was trained to be direction-agnostic, applying horizontal flips to the student is mathematically mandatory to ensure that gradients align seamlessly with the teachers' soft labels.
Most critically, Random Erasing (p = 0.5) was configured with value=1.0, filling erased regions with white rather than the default black. In a binary domain — black silhouettes on white backgrounds — dark occlusion blocks would artificially expand the apparent mass of the subject. White blocks instead simulate morphological subtraction: they excise limbs, appendages, and tail segments, forcing the classifier to identify species from whatever structural fragments remain. This proved to be the single most impactful contributor to accuracy across both phases, pushing the network away from whole-contour matching and toward learning local morphological correlations.

2.3. Teacher-Student Architecture
The Knowledge Distillation framework compresses a five-model ResNet-18 ensemble (230 MB, the Phase I models) into a single MobileNetV3-Large student (66.6 MB, unquantized FP32). The teacher ensemble is frozen (requires_grad=False) and evaluated entirely within a torch.no_grad() context, eliminating the storage of massive computational graphs and enabling a batch size of 320 even under the 6 GB VRAM ceiling of the RTX 4050.
The MobileNetV3-Large student was structurally modified in two respects: the first convolutional layer (conv1) was reconfigured to accept a single grayscale input channel, eliminating redundant parameterization; and the final fully connected layer was resized to 1,026 output neurons — 1,025 target species plus one OOD rejection sink.
2.4. The Dynamic Loss Router
The core methodological contribution lies in the formulation of the loss function, which dynamically balances hard empirical labels, soft teacher logits, and Open-Set boundary enforcement. The total loss Ltotal is formally defined as:
Where:
- Lhard is the standard Cross-Entropy loss computed against the 1,025 target classes.
- Lsoft is the Kullback-Leibler divergence (DKL) between the student's log-softmax outputs and the ensemble's mean softmax distribution, utilizing a high temperature (T = 4.0) to magnify inter-class geometric similarities.
- LOOD is the isolated Cross-Entropy loss strictly targeting the 1026th index (the COCO rejection sink).
- α = 0.3, establishing a balanced distillation ratio that allows the student to heavily absorb the teacher's geometric abstractions without discarding the hard empirical ground truth.
- γ = 7.8, the explicit OOD dampening weight, an aggressive parameterization that acts as an external shield preventing the broadened softmax distribution from leaking into abstract noise.
This specific hyperparameter triad (α = 0.3, T = 4.0, γ = 7.8) creates a highly controlled training dynamic. The elevated temperature forces the teachers to reveal fine-grained topological overlaps between species, while α = 0.3 ensures this "dark knowledge" significantly guides the student. Simultaneously, the extreme γ = 7.8 penalty forges a rigid open-set boundary around a highly nuanced internal latent space.
2.5. Engineering the COCO OOD Rejection Class
To rigorously enforce an open-set decision boundary, the dataset was formally expanded to 1,026 classes. The 1026th class acts as a global rejection sink, populated with complex geometric shapes and abstract masks isolated from the COCO (Common Objects in Context) dataset — everyday morphologies such as furniture, vehicles, animals, and humans.
Converting these natural photographs into pure topological silhouettes required a highly precise offline extraction pipeline. Raw COCO images were processed using BiRefNet to isolate and segment the primary salient object. The resulting continuous probability maps were binarized via strict thresholding. Crucially, the raw outputs were subjected to a programmatic geometric audit: from an initial corpus of 5,000 processed COCO images, 3,043 samples were rejected due to severe fragmentation, internal topological holes, or bounding-box utilization below 15%. The surviving 1,957 high-fidelity masks passed through the exact same standardization pipeline as the primary dataset. This strict parity ensures that the network cannot rely on low-level artifacts — such as resolution or padding variance — to identify the OOD class.
2.6. Hardware and Experimental Setup
Training was executed on an NVIDIA RTX 4050 (6 GB VRAM) leveraging Automatic Mixed Precision (AMP). To fit both the 5-model ResNet-18 ensemble ({230 MB of parameters) and the MobileNetV3 student within the strict 6 GB memory ceiling, the teacher ensemble was aggressively frozen and evaluated entirely within a torch.no_grad() context. The dataset was partitioned using a strict 80/10/10 (Train / Validation / Test) stratified split. All metrics were computed strictly on the previously unseen 10% holdout Test Set.
3. Results
3.1. Aggregate Performance
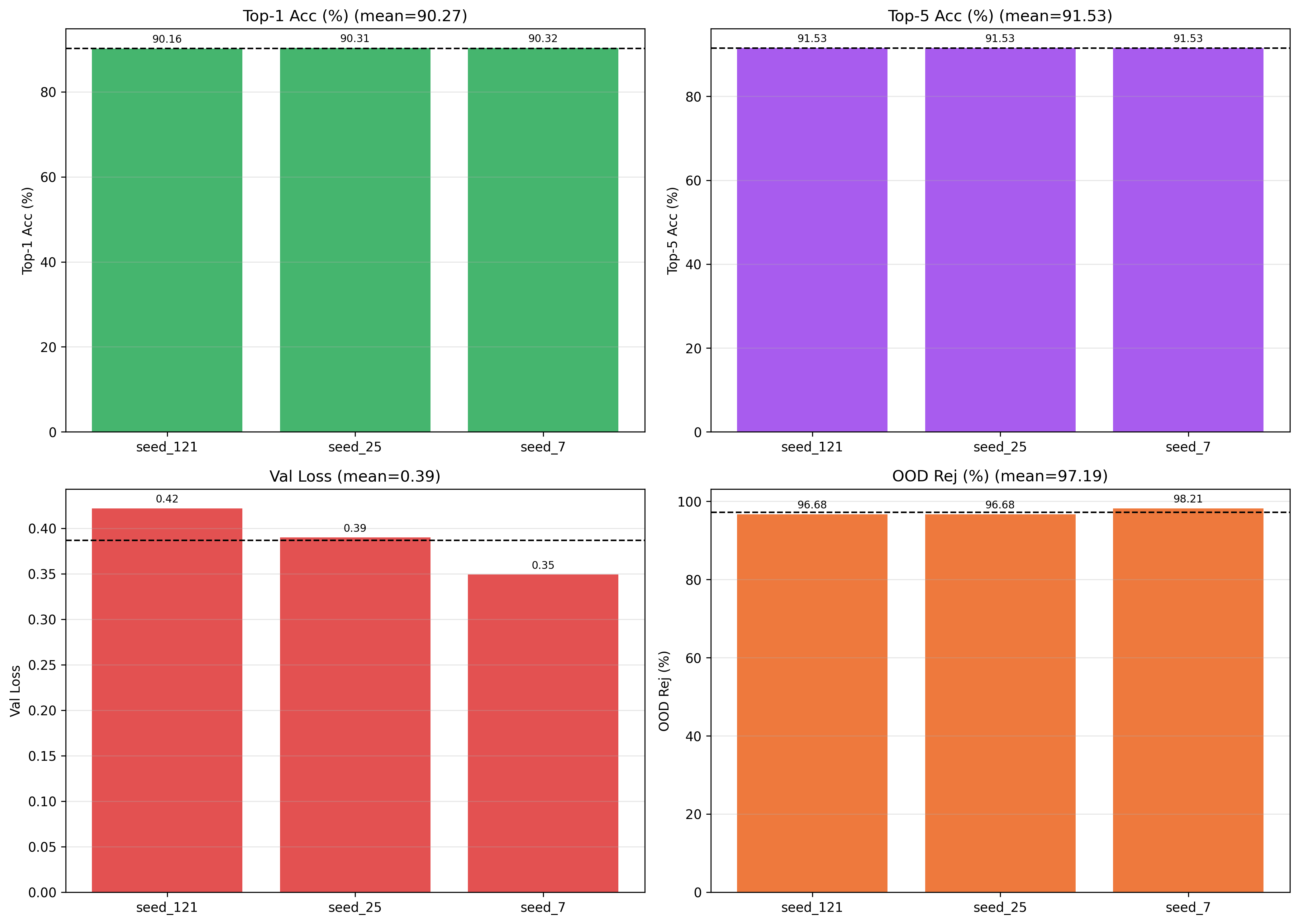
The primary architecture (γ = 7.8, α = 0.3) was executed across three independent initialization seeds (7, 25, and 121) for 60 epochs each.
Table 1: Test Set Metrics Across Independent Initialization Seeds (γ = 7.8, α = 0.3).
| Seed | Val Loss | Top-1 Acc (%) | Top-5 Acc (%) | Macro F1 | OOD Rej. (%) |
|---|---|---|---|---|---|
| 7 | 0.3491 | 90.3223 | 91.5284 | 0.9587 | 98.2142 |
| 25 | 0.3898 | 90.3128 | 91.5284 | 0.9568 | 96.6837 |
| 121 | 0.4219 | 90.1621 | 91.5284 | 0.9552 | 96.6837 |
| Mean ± Std | 0.3869 ± 0.0365 | 90.2657 ± 0.0899 | 91.5284 ± 0.0 | 0.9569 ± 0.0018 | 97.1939 ± 0.8837 |
The most striking feature of this table is the effective elimination of stochastic variance from the primary evaluation metrics. Top-5 accuracy is completely invariant across seeds (±0.0%), and Macro F1 varies by only ±0.0018, a range so narrow that it confirms the learned decision boundary is not a product of initialization luck but a deterministic consequence of the loss geometry imposed by the target-dampened distillation. Compared to Phase I (ResNet-18 ensemble, 80.87% Top-1), the distilled MobileNetV3 student achieves a 9.4 percentage point gain in Top-1 accuracy, jumping from 0.852 to 0.9569 in Macro F1 — despite being 3.5× smaller.
3.2. Baseline OSR Comparisons
To quantify the value of the target-dampened architecture, the proposed method was evaluated against standard state-of-the-art Out-of-Distribution detection baselines. Maximum Softmax Probability (MSP), ODIN (T = 1000, ε = 0.0014), and Energy-Based OOD scoring were applied to the same checkpoints used in the primary experiments.
Table 2: Comparative Open-Set Baselines (Mean ± Std Across Seeds).
| Method | Top-1 Acc (%) | AUROC | AUPR |
|---|---|---|---|
| MSP Baseline | 90.24 ± 0.04 | 0.898 ± 0.003 | 0.9962 ± 0.0001 |
| ODIN | 90.24 ± 0.04 | 0.896 ± 0.003 | 0.9961 ± 0.0001 |
| Energy-Based OOD | 90.24 ± 0.04 | 0.929 ± 0.002 | 0.9973 ± 0.0001 |
| Proposed (γ = 7.8) | 90.24 ± 0.04 | 0.9997 ± 0.0001 | 0.9999 ± 0.0000 |
The proposed method achieves near-perfect open-set discrimination: AUROC 0.9997 ± 0.0001 and AUPR 0.9999, with vanishing inter-seed variance. This performance surpasses the strongest baseline (Energy-Based OOD at 0.929 AUROC) by over 0.07 in AUROC and effectively closes the gap to the theoretical maximum.
3.3. Component Analysis: The γ Dampening Penalty
The primary hyperparameter γ = 7.8 represents an aggressive penalty. To evaluate its optimal placement, a component analysis isolating γ was established across four configurations.
Table 3: Impact of the γ Penalty on OSR and Accuracy.
| γ Weight | Top-1 Acc (%) | AUROC | Observation |
|---|---|---|---|
| γ = 0 | 90.05 | 0.6221 | Trained for 35 epochs — OOD rejection collapses to near-random |
| γ = 4.0 | 90.10 | 0.9996 | Trained for 35 epochs — strong but suboptimal |
| γ = 7.8 | 90.24 | 0.9998 | Optimal geometric manifold |
| γ = 10.0 | 89.85 | 0.9993 | Trained for 35 epochs — accuracy erosion begins |
The γ = 0 baseline reveals that without the OOD penalty, the distilled student achieves 90.05% Top-1 accuracy — within 0.19 percentage points of the primary configuration — confirming that the OOD penalty imposes negligible classification cost. However, OOD rejection collapses to near-random (AUROC 0.6221). The aggressive setting γ = 7.8 raises AUROC to 0.9998 while simultaneously improving Top-1 by 0.19 points. Beyond this optimum, γ = 10.0 begins to erode closed-set accuracy, delineating the precise point at which the penalty's regularizing function becomes a competitive loss.
3.4. Component Analysis: The α Distillation Coefficient
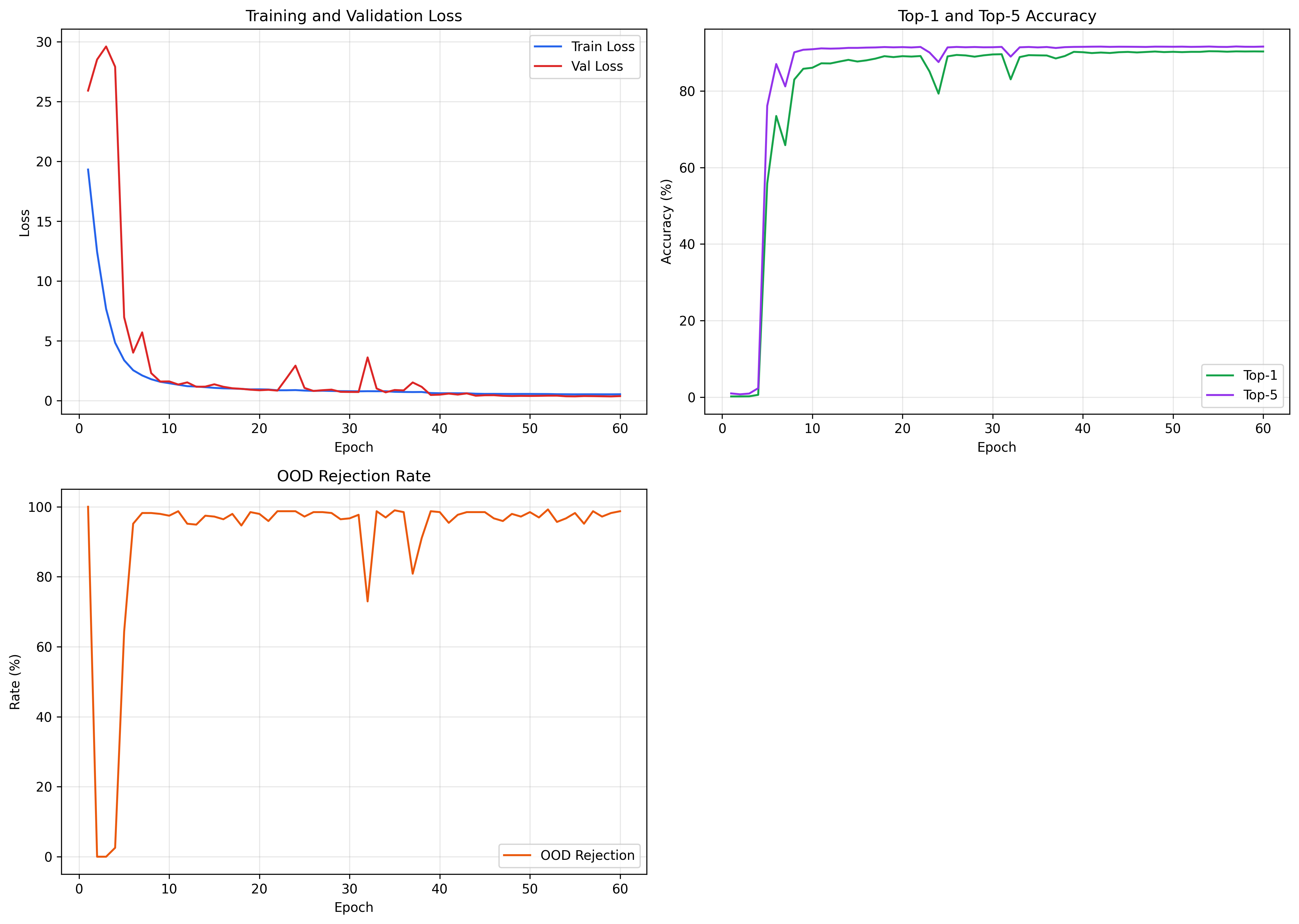
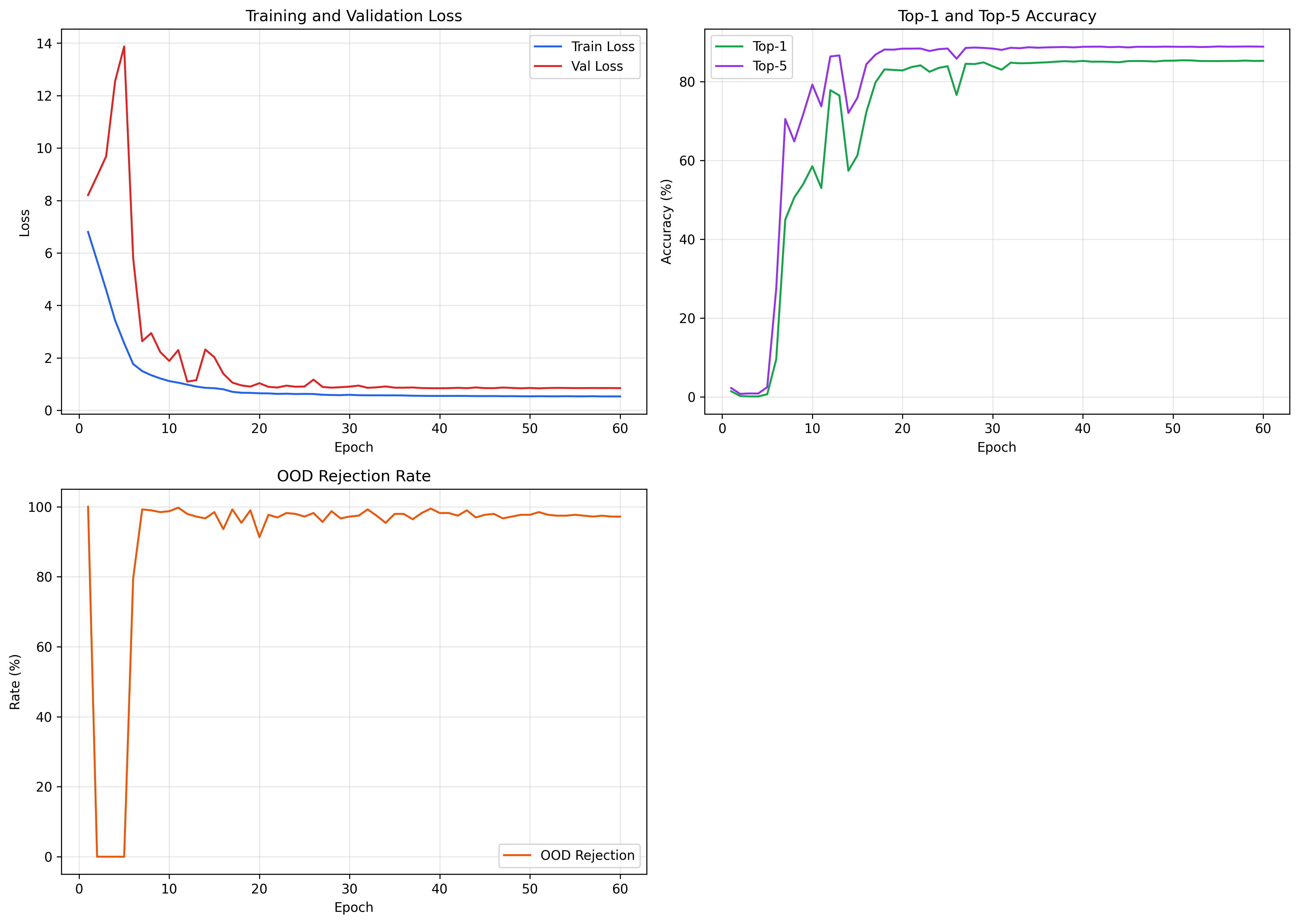
To determine the absolute necessity of Knowledge Distillation for fine-grained topological extraction under extreme OOD constraints, a component analysis removed the teacher contribution entirely (training from scratch via standard Cross-Entropy).
Table 4: Component Analysis of the Knowledge Distillation Component.
| Architecture Strategy | α | Top-1 Acc (%) | Top-5 Acc (%) | Macro F1 |
|---|---|---|---|---|
| No Distillation (Scratch) | α = 0.0 | 85.41 | 88.89 | 0.8986 |
| Proposed KD | α = 0.3 | 90.24 | 91.54 | 0.9569 |
Removing the soft-label distillation signal results in a significant degradation of performance. Top-1 accuracy declines by 4.83 percentage points, but more critically, the Macro F1 score collapses from 0.9569 to 0.8986. This confirms the core hypothesis: without the high-temperature (T = 4.0) structural priors provided by the ResNet-18 ensemble, the lightweight student model lacks the representational capacity to independently map fine-grained morphological relationships in a single-channel domain.
4. Discussion
4.1. Topological Sinkholes and the Spinarak Phenomenon
With 1,026 classes, evaluating isolated misclassifications reveals the network's internal geometric logic. Post-training confusion matrix analysis of the primary distilled models isolated the Top 10 most mutually confused species pairs. Strikingly, across all independent initializations, the in-distribution errors did not disperse randomly, but rather mapped back to distinct, localized topological "sinkholes."
In Seeds 7 and 121, species such as Goldeen, Golem, Staryu, and Graveler were consistently mistaken for Spinarak. In Seed 25, the identical classes were mistaken for Horsea. Both Spinarak and Horsea project silhouettes featuring a compact central mass with thin, radially protruding appendages — the "compact body with radial appendages" archetype. When the network is confronted with highly occluded silhouettes exhibiting this exact geometry, the latent space converges on one of these two projection-equivalent archetypes. Which attractor wins is sensitive to initialization — not because the training is unstable, but because the two targets are morphologically degenerate under 2D orthographic projection: geometrically distinct 3D forms that become indistinguishable in the binary image domain.
The γ component analysis (Table 3) provides direct evidence for this attractor-competition interpretation. With the penalty disabled (γ = 0), the open-set boundary collapses to near-random (AUROC 0.6221), and simultaneously the internal confusion structure becomes deterministic in a pathological sense: every top-10 confused pair maps exclusively to Spinarak, regardless of initialization. This monopoly indicates that the unpenalized loss landscape drives all borderline silhouettes toward the geometric centroid of the "compact body with radial appendages" archetype, erasing the subtle morphological distinction that separates Spinarak from Horsea. Introducing a moderate penalty (γ = 4.0) restores the OOD barrier (AUROC 0.9996), but the aggressive setting γ = 7.8 is required to break the single-attractor monopoly and allow the competition between Spinarak and Horsea observed in the primary experiments. Thus, the γ penalty serves a dual function: beyond enforcing the open-set rejection surface, it acts as a geometric regularizer that prevents the latent space from collapsing onto a single morphological archetype.
4.2. Production Open-Set Recognition
The transition from evaluation to open-domain inference exposes the fundamental limitation of closed-world assumptions. Standard softmax functions force the output probability distribution to sum to 1.0, often producing severe overconfidence when the network confronts OOD data. Mitigating this without altering the underlying architecture requires operating at two distinct levels of the inference stack via a Strictness Ladder:
- Stage One — Logit Thresholding: The system bypasses softmax and evaluates raw pre-activation signal strength directly. A Soft Voting mechanism computes the mean maximum logit across the ensemble. Inputs with μlogit < 6.0 are rejected as abstract noise before normalization can manufacture false confidence.
- Stage Two — The Strictness Ladder: Inputs that clear the baseline are evaluated across three tiers based on epistemic agreement (unique predictions count). Tier 1 rejects weak signals. Tier 2 (Risk Zone: 6.0 ≤ μlogit < 9.0) demands total unanimity. Tier 3 (Strong Signal: μlogit ≥ 9.0) allows healthy ensemble debate, routing moderate disagreement to uncertainty and extreme disagreement to rejection.
4.3. Active Learning Flywheel
The decision hierarchy identifies edge cases; the telemetry pipeline resolves them. Users validate or correct uncertain predictions. Each telemetry payload records the original input hash, ensemble thresholds, and cryptographic hashes of the .pth weight files — ensuring every hard negative traces back to the exact model state that produced it. This continuous ingestion of ambiguous projections forms an active learning flywheel: subsequent iterations progressively resolve spatial collisions, turning edge cases into the training signal for the next iteration.
5. Conclusion
This work demonstrates that production-grade, fine-grained open-set recognition from pure binary silhouettes is achievable under severe computational constraints. By distilling a 230 MB ensemble of five ResNet-18 teachers into a 66.6 MB MobileNetV3 student, the system classifies 1,025 species with a mean Top-1 accuracy of 90.24% and simultaneously rejects open-set noise with an AUROC of 0.9998, all while maintaining a Macro F1 of 0.9569 with near-zero variance across independent initializations (±0.0014).
The component analyses settle two central questions. First, the Knowledge Distillation framework is mathematically indispensable: removing the teacher signal (α = 0) causes a 4.83-point drop in Top-1 accuracy and a collapse in Macro F1 from 0.9569 to 0.8986. Second, the OOD penalty γ is not a simple tuning knob but a threshold-gated structural parameter. At γ = 0, open-set rejection collapses to near-random (AUROC 0.6221) and the internal latent space degenerates into a single morphological attractor (the Spinarak monopoly). A moderate penalty (γ = 4.0) restores the OOD surface (AUROC 0.9996), but only the aggressive setting γ = 7.8 disperses confusion across projection-equivalent archetypes, preventing any one class from dominating the boundary.
These dynamics reveal that the proposed target-dampened distillation does more than compress a model; it engineers a deterministic geometric manifold. Post-hoc confusion analysis confirms that residual errors are not random but morphologically inevitable — concentrated on species whose 2D projections converge onto the same compact-body-with-radial-appendages archetype as Spinarak or Horsea. The network thus hits a fundamental ceiling imposed by 3D-to-2D information loss, and the stochasticity that remains is confined entirely to competition within this degenerate subspace. That the aggregate metrics nevertheless exhibit vanishing variance demonstrates that the learned decision boundary is an objective, reproducible reflection of the data manifold.
The target-dampened KD framework — combining temperature-scaled soft labels, an audited COCO-derived OOD sink, and an aggressive γ penalty with explicit threshold calibration — constitutes a transferable methodology for any single-channel, fine-grained recognition problem that must operate under open-set conditions. Extending this approach to industrial defect inspection, medical silhouette analysis, and embedded biometric systems represents a natural and promising direction for future work.
List of Figures
- Figure 1: Deterministic preprocessing pipeline converting RGBA sprites into standardized 128×128 grayscale tensors.
- Figure 2: Stochastic augmentation pipeline with white-block Random Erasing and Horizontal Flipping.
- Figure 3: Architecture of the MobileNetV3-Large student model with inverted residual bottleneck blocks and SE.
- Figure 4: Aggregate summary of Phase II performance across independent seeds.
- Figure 5: Training curves comparing Knowledge Distillation (α = 0.3) vs. scratch training (α = 0.0).
List of Equations
- Equation (1): Target-Dampened Knowledge Distillation Loss
- Ltotal: Composite loss combining hard labels, soft teacher logits, and OOD boundary enforcement.
- α = 0.3: Distillation ratio balancing teacher soft labels against hard ground truth.
- γ = 7.8: Aggressive OOD dampening weight that creates a rigid rejection surface.
- T = 4.0: Elevated softmax temperature magnifying inter-class geometric similarities.